A project that implements a deep learning model for extracting emotions from the given text.
Basic Steps Involved
Dataset
The Twitter Emotion Dataset is used for training the model. The dataset consinsts of three folders - Train, Test and Labels for test (For evaluating and getting the accuracy). The train folder consists of a large number of tweets labelled with corresponding informations. The Hugging Face’s nlp package is downloaded firstly and then the ‘emotion’ dataset is downloaded from it.
Tokenize the data
The tweets cannot be passed directly to the model and it requires to be tokenized. Tokenizing involves mapping each unique word to a particular token/number. We also set the limit to 10000 words and other less frequently appering words are ignored.
tokenizer = Tokenizer(num_words=10000, oov_token='<UNK>')
tokenizer.fit_on_texts(tweets)
After tokeninizing, the tweet ‘I didn’t feel humiliated’ is changed to [2, 139, 3, 679] which the model understands.
Padding and truncating data
The dataset consists of tweets of varying length which can be problematic. After visualizing the dataset it is found that the avg length of tweets are between 10-20 and very few exists with length more than 50. Therefore each tweet is changed to a seqence of length 50 and the ones greater than will be truncated and split.
The classes present in the dataset are ‘joy’, ‘sadness’, ‘surprise’, ‘fear’, ‘love’ and ‘anger’. These classes also needs to be labelled from 0-6 before implementing the network.
Creating the model
Now that the data is processed to a proper format, model can be created. It is implemented using the sequential class from keras consisting of following layers :
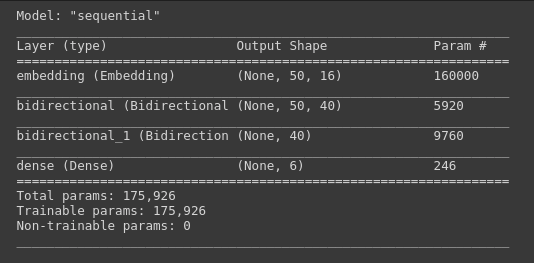
Like other multi-class classification problems, here also categorical crossentropy is used as the loss functions.
Evaluation
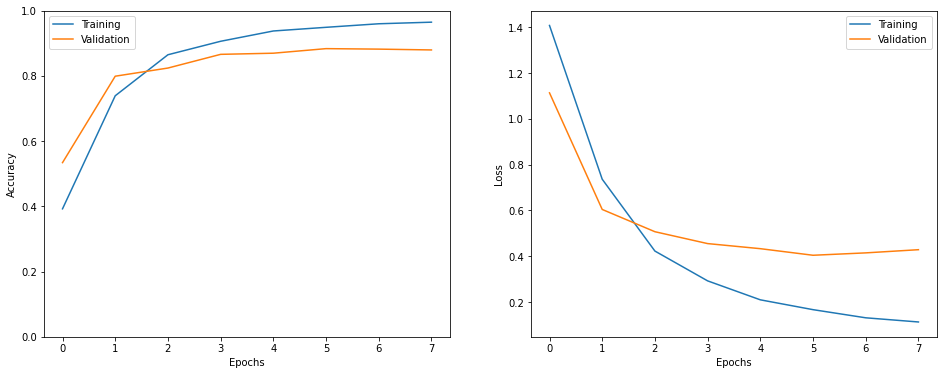 Like other multi-class classification problems, here also categorical crossentropy is used as the loss functions.
Like other multi-class classification problems, here also categorical crossentropy is used as the loss functions.
Also the confusion matrix below justifies the efficiency of the model.
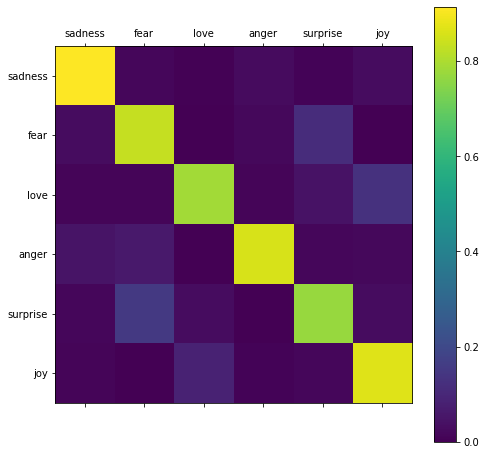
Working on User Input
Although the model got good accuracy scores it doesn’t mean it will be as good for every user inputs, still it does work for most of the time. This lack of performance shows the need for a better model or a better dataset even.
Open the notebook in Google Colaboratory : ![]()