An article written by Margaret Maynard-Reid (ML GDE) and Me originally submitted to ICLR 2022 Blog Post Track.
Introduction
In this blog post, we discuss the key points of the paper “Do 2D GANs Know 3D Shape? Unsupervised 3D Shape Reconstruction from 2D Image GANs” (GAN2Shape) by Pan et al. We will discuss both the theory and code in the author’s GitHub repository and use a demo Colab notebook to show how GAN2Shape is able to transform 2D images to 3D images in multiple view images format.
The GAN2Shape paper presents the first attempt to directly mine 3D geometric cues from GANs trained on 2D RGB images. The technique can be used in very interesting real world scenarios such as image editing of relighting and object rotation after reconstructing 3D shapes from 2D images.
The previous attempts of 3D reconstruction using GANs have a number of limitations such as requiring 2D keypoint or 3D annotations, heavy memory consumption because of reliance on explicitly modeling 3D representation and rendering during training, lower 3D image generation quality than 2D counterparts, or assumptions such as object shapes are symmetric.
The GAN2Shape paper was the first attempt to reconstruct the 3D object shapes using GANs pretrained on 2D images only, without relying on the symmetry assumption of object shapes. It’s able to generate highly photo-realistic 3D-aware image manipulations: rotation and relighting without using external 3D models.
Unsup3D
Unsup3D is an unsupervised 3D reconstruction model proposed by Shangzhe Wu et al. in CVPR 2020 (Best Paper Award). It uses four individual autoencoder networks to decompose a single 2D image based on factors of view, lighting, depth and albedo, assuming they are symmetric. GAN2Shape adopts Unsup3D architecture and improves upon it by making use of StyleGAN2 hich we will discuss in more detail below. GAN2Shape was a paper that kept Unsup3D as a benchmark for all the experiments.
How GAN2Shape Works?
Now that you have the background info on 3D deep learning and GAN variants related to the GAN2Shape paper, let’s take a look at how GAN2Shape works.
The complex architecture and training of GAN2Shape can be broken down into three steps and we will be explaining the theory behind each of them. In addition, we will walk through its code implementation and add links to all the important modules and functions from the official GAN2Shape GitHub repository.
Step 1: Creating Pseudo Samples
The first step in the GAN2Shape model architecture is the generation of pseudo samples. In this step, an input 2D image is passed onto 4 networks: view (V), light (L), depth (D) and albedo (A), and using the outputs of each of these networks we reconstruct a set of 2D images with different viewpoints and lighting conditions, which are referred to as pseudo samples. This method to recover 3D shape from a single view 2D image was introduced in Unsup3D by Shangzhe Wu et al. as mentioned above.
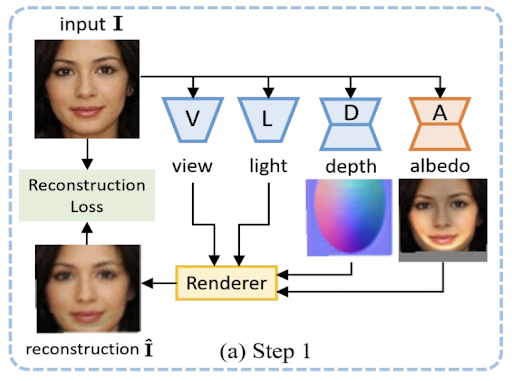
This problem of decomposing a 2D image to the four above-mentioned factors is an ill-posed one and hence we have to make an assumption inorder to solve it. So one thing we assume is that all objects including faces and cars have a convex shape prior, which provides a hint on initial viewpoint and lighting conditions.
To implement this firstly the depth map is initialized with an ellipsoid shape. The function that predicts depth, albedo, viewpoint, lighting are implemented using individual neural networks: The depth and albedo are generated by encoder-decoder networks. The viewpoint and lighting are measured using simple encoder networks.
In step 1 we only train the Albedo network, to optimize it we reconstruct the original input image from these four factors via a rendering process and then a reconstruction loss is also calculated by taking a weighted combination of L1 loss and Perceptual loss, introduced by Johnson et al.
To create pseudo samples, we randomly sample different lighting directions and viewpoints along with the depth and albedo network outputs we have obtained. If our input is a 2D image of a face, the pseudo samples will contain a set of images that indicates how the lighting changes when the face is rotated at different angles.
Step 2: Obtain Projected Samples
The pseudo samples we have at this point are useful images showing different viewpoints of the image and indicate how the change in light affects the image but at the same time it consists of unnatural shadows, distortions, so our next step is to transform them into photorealistic images.
This is where StyleGAN2 comes into picture. In step 2, we use a pretrained StyleGAN2 generator for GAN inversion and a pretrained StyleGAN2 discriminator for calculating the reconstruction loss in order to optimize the encoder network.
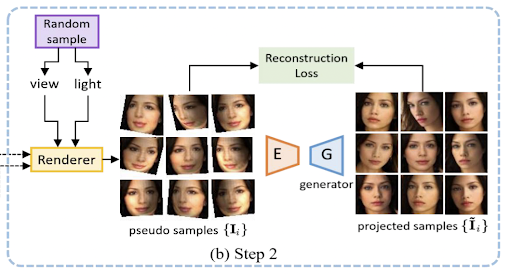
We perform GAN inversion to these pseudo samples and convert each sample into a latent vector using a standard ResNet encoder. These latent vectors are then projected back to their original space using the StyleGAN2 generator. This way we project the pseudo samples into a GAN image manifold making them more photorealistic, and these new samples are termed as projected samples.
While performing GAN inversion the latent vectors obtained for the pseudo samples are added to the latent representation of the original input.This way we can make the generated images look much more realistic without actually changing other features such as face orientation and shading.
To measure the difference between the generated projected samples and the input pseudo samples, we make use of a discriminator network similar to the one in StyleGAN2 architecture. Both generated and original set of images are passed through the discriminator and the distance between the obtained features along with a regularization term is used as the reconstruction loss for this step. This method was proposed by Pan et al. The reconstruction loss further ensures that these generated samples will not have different lighting conditions and viewpoints compared to the pseudo samples.
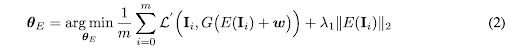
The reconstruction objected for the encoder is represented in Eq.2, where G is the StyleGAN generator, E is the encoder Ľ represents the distance metric which is used to calculate the loss between the generated and original input features. A regularization term is further added to prevent the latent offset from growing too large.
Step 3: From 2D to 3D
After Step 2 we have projected samples which are sets of photorealistic images of a particular object with multiple viewpoints and lighting conditions. To learn its 3D shape, we again make use of the four networks View, Light, Depth and Albedo used in Step 1.
The main differences in Step 3 are that :
- View and Lighting conditions are predicted using the projected samples generated in Step 2, and the V and L encoder networks take the projected samples as the input.
- The reconstruction loss is computed in a different way compared to Step 1, and the loss is used to optimize all four networks.
- For generating the 3D view, viewpoint and lighting obtained from the projected samples are used for rendering, and the images generated at this stage are more photorealistic and better represents the 3D view of the input image.
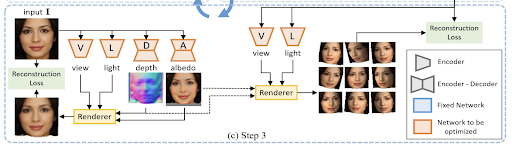
In step 3 firstly the albedo and depth factors are predicted by the respective encoder-decoder networks using the original input. The viewpoint and lighting are predicted by the corresponding encoder networks using the projected samples generated in Step 2. All the 4 networks are jointly trained to reconstruct the original image and the reconstruction objective formulated in Eq.3, where I and Ĩ represents the original input image and the projected samples respectively. A smoothness loss is also added for overcoming gradient locality as proposed by Zho et al.
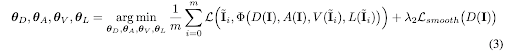
The four networks are similarly trained to render the 3D view of the input image, similar to how pseudo samples were generated in Step 1. These rendered sets of images are much more photorealistic in representing the 3D view compared to the pseudo samples.
Iterative self-refinement
One important note about this GAN2Shape model is that the training has more than one cycle of repeating the above 3 steps to transform a 2D image into a 3D image; however, those steps need to be repeated to refine the 3D image. The paper used four cycles (or stages) to repeat these 3 steps mentioned above.
Another note about the process: The GAN2Shape model needs to be separately trained for each 2D input image, which involves repeating the 3 training steps discussed above for 4 cycles (or stages) and the output thus obtained would contain a set of images that can be used to construct a multi-view 3D image.
Results
The GAN2Shape model was successful in recovering 3D shapes from 2D images of numerous objects such as cars, buildings, human faces, cats etc. Prior to GAN2Shape, Unsup3D was the state of the art model for obtaining the 3D view of an input 2D image. But the model assumed every object to be symmetric and the lighting and textures were added accordingly to the 3D shape. GAN2Shape results showed that the model was successful even without the 3D assumption, producing a more realistic 3D view. The image below compares the performance of the two models.

GAN2Shape works well for images of human or cat faces where a convex shape prior provides a hint on the viewpoint and lighting condition, but fails when this is not the case. Due to this GAN2Shape was observed to not perform well on the LSUN horse dataset.
Conclusion
In this post, we gave a brief introduction to 3D deep learning, GANs, StyleGAN2, and Unsup3D . Then we discussed in detail the key steps of GAN2Shape: how to transform a 2D image into 3D shapes, by using Unsup3D and StyleGAN2D. We demonstrated the training process with a Colab notebook to show the input image and the generated 3D images.
In summary, GAN2Shape is able to generate 3D shapes from 2D images which are readily available, without any additional annotations, 3D models or assumptions of object symmetry, and provide better results than previous 3D construction GAN models.