An article written by Margaret Maynard-Reid (ML GDE) and Me originally published in Towards Data Science.
3D deep learning is an interesting area with a wide range of real-world applications: art and design, self-driving cars, sports, agriculture, biology, robotics, virtual reality and augmented reality. This blog post provides an introduction to 3D deep learning: 3D data representations, computer vision tasks and learning resources.
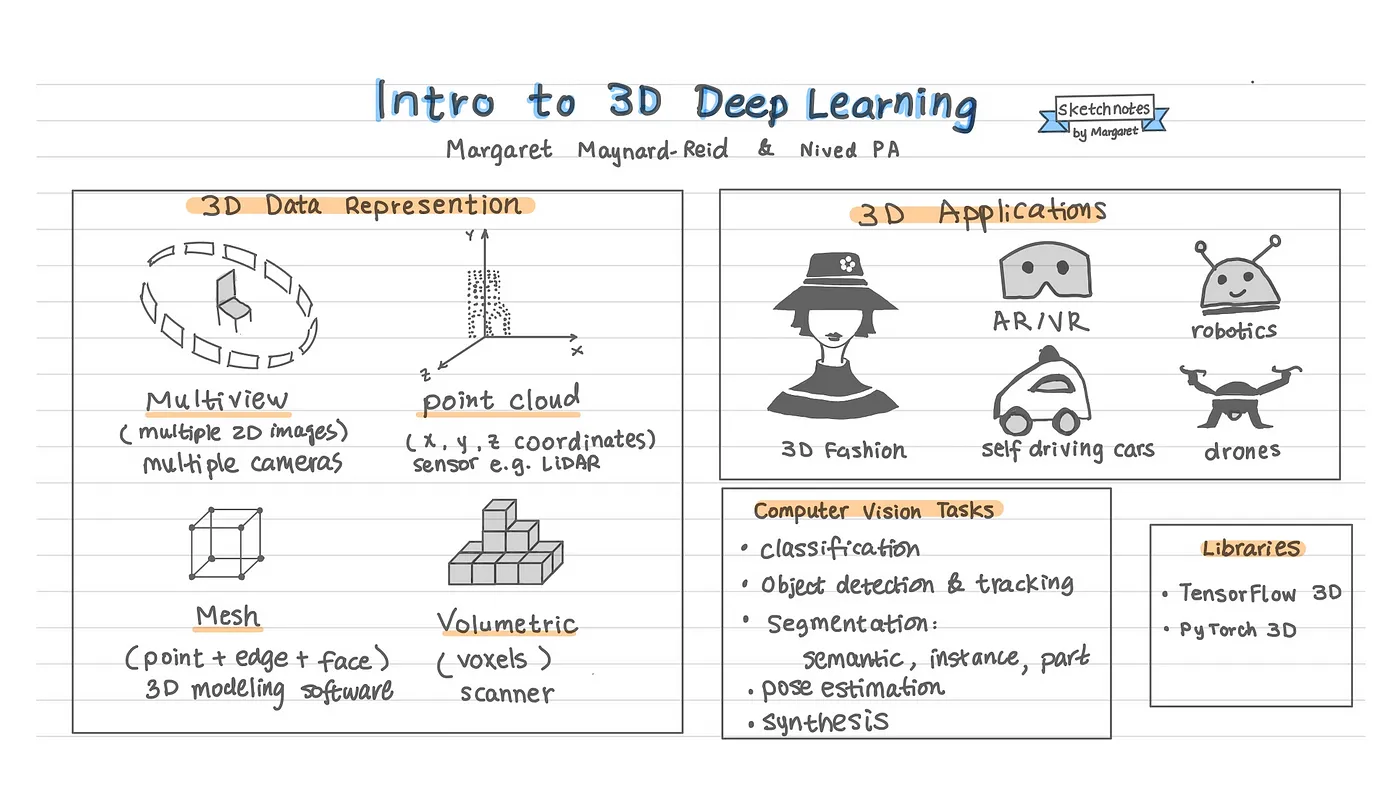
3D Data
Data is super important for training machine learning models. One of the biggest differences between 2D and 3D deep learning is the data representation format.
Regular images are typically represented in 1D or 2D arrays. 3D images, on the other hand, can have different representation formats and here are a few most popular ones: multi-view, volumetric, point cloud, mesh and volumetric display. Let’s take a look at each data representation illustrated with images.
Multi-view images
These can be captured by positioning multiple cameras that take photos from different angles of the same object or scene. Here is what a chair looks like with images from ShapeNet which is a richly-annotated, large-scale repository of shapes represented by 3D CAD models of objects.

Point cloud
In a point cloud dataset, each image is represented by a set of points (x, y, z coordinates), which are collected from raw sensors. Point cloud data are typically captured by LiDAR sensors or converted from mesh data.
Here is what a chair looks like in Point cloud representation from the ModelNet10 dataset.

Mesh
A mesh is the typical building block for 3D modeling with software such as Blender, Autodesk Maya or Unreal Engine etc. Unlike in point cloud where each 3D object is made of points, the mesh representation consists of a set of points and in addition the relationship of these points (edges) and faces. One type of mesh is polygon mesh with faces in the shape of triangles or quads.

Volumetric display
In the volumetric representation, each image is solid and made of voxels: the 3D equivalent of pixels in 2D images.
3D modeling software such as Blender can be used to voxelize 3D models and here is an example of a voxelized bunny:

Volumetric representation can be obtained with real-time scanning or converted from 3D point cloud or meshes. Here is an example from scan-net.org, which has RGB-D scans of indoor scenes with semantic voxel labeling.
3D Computer Vision Tasks
Just like 2D computer vision, 3D tasks include image classification, segmentation, pose estimation and image synthesis with generative models. Below we will go over a few examples of these tasks. And since 3D data has so many different representations, note that the examples we mention below likely will only cover some of the 3D data formats.
3D Image Classification
Image classification is a well-solved problem in both 2D and 3D computer vision.
3D data classification involves the task of identifying a single 3D or multiple 3D objects present in a scene. It would enable us to recognize and identify objects by capturing their shape, size, orientation etc. which is vital when dealing with real-world applications such as augmented reality (AR), self-driving cars, and robotics.
This task is similar to 2D image classification with the differences lying in the model architecture. VoxNet (2015) was one of the initial works that made use of 3D CNNs for single 3D object detection. It takes in 3D volume data or a sequence of 2D frames as inputs and applies a 3D kernel for convolution operation. 3D CNNs are a powerful model for learning representations for volumetric data. More recent works such as SampleNet (2020) introduces techniques to sample point clouds which include points representing a visual scene, resulting in improved classification performance as well as for other tasks such as 3D reconstruction.
Here is a great tutorial on Keras.io for learning 3D image classification: Point Cloud Classification with PointNet.
3D Object Detection & Tracking
Object detection and tracking in 3D is similar to the task in 2D but with additional challenges. 3D object detection task we work with either voxels or points.
3D object detection and tracking is very useful in self-driving cars. We can use RGB images, point cloud data or fused data input from both camera and sensor (LiDAR) point clouds to train 3D object detection and tracking.
Object detection and tracking can also be used in augmented reality to superimpose virtual items into the real world scenes.

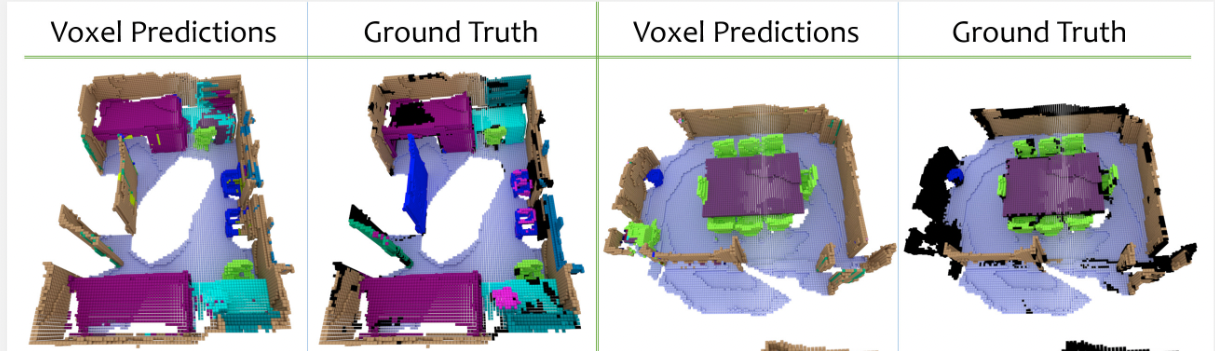
3D Image Segmentation
As in 2D image segmentation tasks, 3D image segmentation also includes semantic, instance and part segmentation.
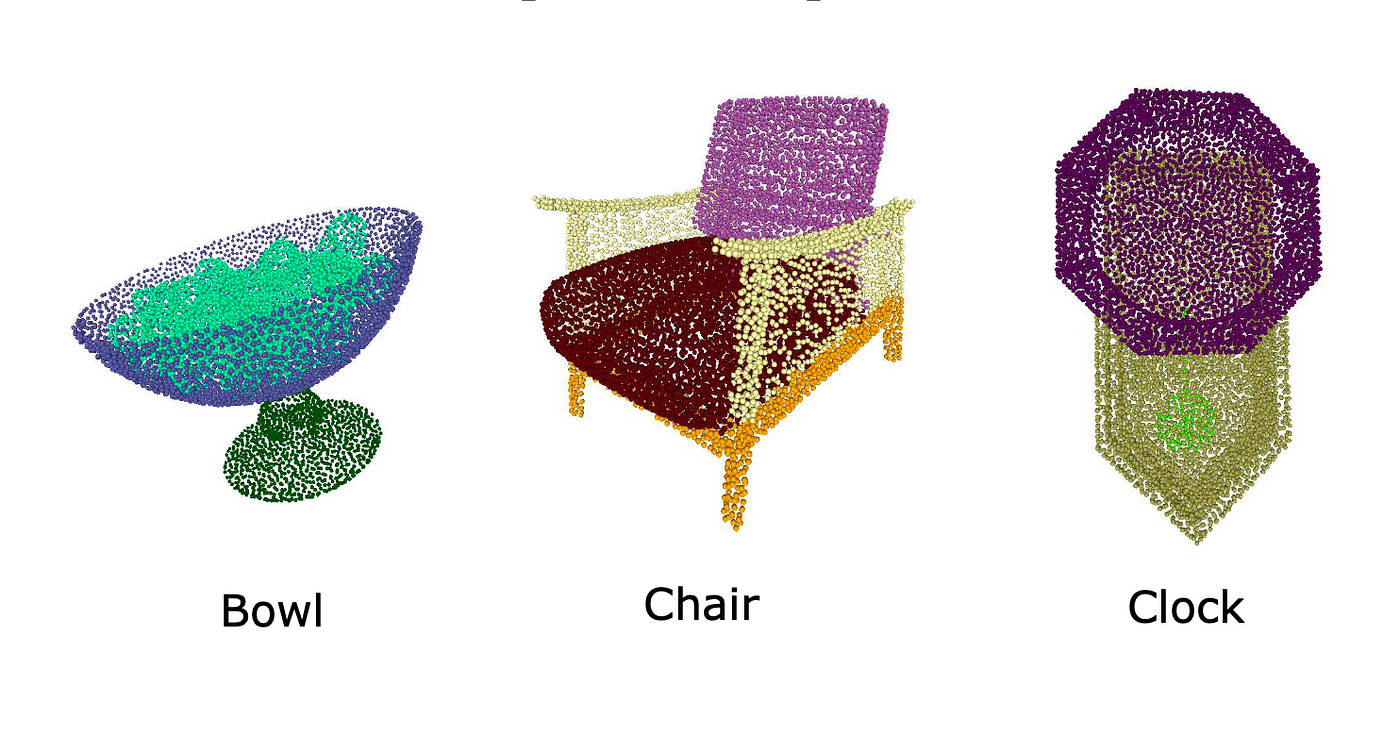
Depending on the 3D data representation, different techniques are utilized for the segmentation task. Some of the popular 3D dataset for segmentation includes ScanNet, ShapeNet and Semantic3D.
Some applications of 3D segmentation include using drones for scene analysis, 3D map reconstruction, and medical diagnosis. Interestingly, semantic segmentation also helps with depth estimation.
3D Pose Estimation
3D pose estimation is a process involving the prediction of the actual spatial positioning of a 3D object from a 2D image given as input. Once we obtain information such as 3D rotation and translation of an object in 2D image, we can transform it into 3D space. This problem is highly active in the field of robotics. A robot might be able to see various objects using a camera, but merely seeing an object is not enough to actually grasp it.
For tackling this problem, usually a number of significant features known as keypoints are detected, identified and tracked for each object. One of the early works addressing this problem is by Shubham Tulsiani et.al (2015), where they have introduced a CNN based approach for reliably predicting both viewpoints and keypoints of an object from a 2D image.

Other important applications of 3D pose estimation include augmented reality and virtual try-on in fashion.
3D Image Reconstruction
3D Image Reconstruction involves the task of understanding the 3D structure and orientation of an image from keypoints, segmentation, depth maps and other forms of data representing knowledge of the 3D model. With the abundance of data, deep learning based techniques have also been popular in solving this problem. These works are based on different models such as CNNs, RNNs, Transformers, VAEs and GANs.
Multi-view reconstruction
This is a task of reconstructing the 3D view of an object using a collection of 2D images representing the scene. The deep learning model based on this technique extracts useful information from the images and explores the relationship between the different views.
Single-view reconstruction
In single view reconstruction the 3D view of the object is done using a single 2D image. This is a much more complex task that requires the model to infer geometrical structure and visual features such as texture and shading, just from an image representing a single view of the object. However there has been numerous research in the field such as GAN2Shape, PHORUM that has demonstrated success in generating photorealistic 3D structures with accurate color, texture and shading representations.
3D reconstruction with NeRF
NeRF explores the task of 3D reconstruction using a single continuous 5D coordinate as inputs. The coordinate represents the spatial location and the viewing directions. It outputs the volume density and the view dependent RGB color at the given location. This minimizes the error that is introduced when rendering multiple images which was previously used for 3d reconstruction tasks.
This concept was introduced by the paper: Representing Scenes as Neural Radiance Fields for View Synthesis [Project][Paper][Code]. Here is also a great tutorial on Keras.ion on this https://keras.io/examples/vision/nerf/.
Learning resources
We would like to share a few learning resources that helped us to learn 3D deep learning.
Keras.io has several 3D deep learning tutorials as mentioned above.
How to represent 3D Data is an excellent post with more details on 3D data representation. 3D Deep Learning Tutorial by the SU Lab at UCSD (University of San Diego) provides a great overview of 3D deep learning. The GitHub repo 3D Machine Learning has a collection of 3D datasets, models and papers etc.
There are two 3D deep learning libraries: TensorFlow 3D and PyTorch3D. This blog post 3D Scene Understanding with TensorFlow 3D goes into details about TensorFlow 3D models. And these excellent PyTorch3D tutorials have Colab notebooks that you can explore hands-on.
Summary
This post provides an overview of 3D deep learning: the basic terminologies, 3D data representation and the various 3D computer vision tasks. We have shared a few learning resources which you may find helpful for getting started with 3D deep learning.
About the authors —
Margaret Maynard-Reid is an ML engineer, artist and aspiring 3D fashion designer. Nived PA is an undergraduate student of Computer Engineering from Amrita University.